Just letting anyone who sees this blog or who is still checking back know that I have moved to a new domain. I am now Psycho Cod3r. My dosfanboy blog is being treated as an archive of my past computing life, and there will be no further updates to it. My new blog is updated daily and has a myriad of articles on DOS, Linux, programming, cyber security, and other topics. See you there! 🙂
Writing a simple search engine in PHP
Writing a search engine for your LAMP server is actually fairly simple. I realized I could simply use grep for the search algorithm and have the search engine use regular expression metacharacters. I mean, why reinvent the wheel? Of course, a search engine that crawls the entire web will be more complicated; this one just searches the local web server.
Here is the code I’ve written. It uses less than ten lines of PHP code, and even what I have here has some parts that are rather superfluous (I should probably streamline it)…
1 <!DOCTYPE html>
2 <!-- A simple search engine written in PHP -->
3
4 <html>
5 <head>
6 <title>Search</title>
7 </head>
8
9 <body>
10 <?php
11 if( is_null( $_GET['query'] ) ){
12 ?>
13 <!-- No query performed yet -->
14 <form action="<?php echo $_SERVER['PHP_SELF']; ?>" method="get">
15 Enter a query:<br>
16 <input name="query" type="text"><br>
17 <input type="submit" value="Search">
18 </form>
19 <?php } else { ?>
20 <!-- Query has been performed -->
21 <?php
22 exec( "grep -ril \"" . $_GET['query'] . "\" *", $files );
23 $length = sizeof( $files );
24 for( $i = 0; $i < $length; $i++ ){
25 echo( "<a href=\"" . $files[$i] . "\">" . $files[$i] . "</a><br>\n" );
26 }
27 ?>
28 <?php } ?>
29 </body>
30 </html>
Since the search algorithm is simply a front-end for grep, I didn’t really have to think about its implementation. Basically, the script has a decision statement that looks at the superglobal variable $_GET['query']. If it’s null, that means the query hasn’t been submitted yet, so it shows the prompt for the query. If it’s not null, it shows the results of the query, which is of course a regular expression. The results are obtained by greping the local server filesystem and returning all files that contain that pattern.
One thing that makes PHP code somewhat confusing is the way you can have a PHP script interleaved with HTML code. It’s one of those things you just have to get used to.
Possible enhancements include:
- Using
egrepinstead ofgrepso the user can use extended regular expressions. - Adding the ability to search for images, videos, and other media on the server, rather than just web pages (this could be done by returning any such media that are used by pages that match the pattern).
- Searching filenames in addition to file contents (you could use
findfor this). - Using a ranking algorithm (currently it just lists them in the canonical order returned by
grep). - And of course adding CSS and other formatting to make the page more aesthetically pleasing.
Making a Snoopy calendar in Unix
For those of you who don’t know, the Snoopy calendar is a gimmick of the hacker culture. It basically refers to a line printer calendar for 1969 featuring the iconic beagle from Peanuts, that apparently hangs on the wall of every Real Programmer’s office. I’m not entirely certain of the origins of this meme, but it dates back at least to the humorous essay Real Programmers Don’t Use Pascal, which was posted to Usenet back in 1983.
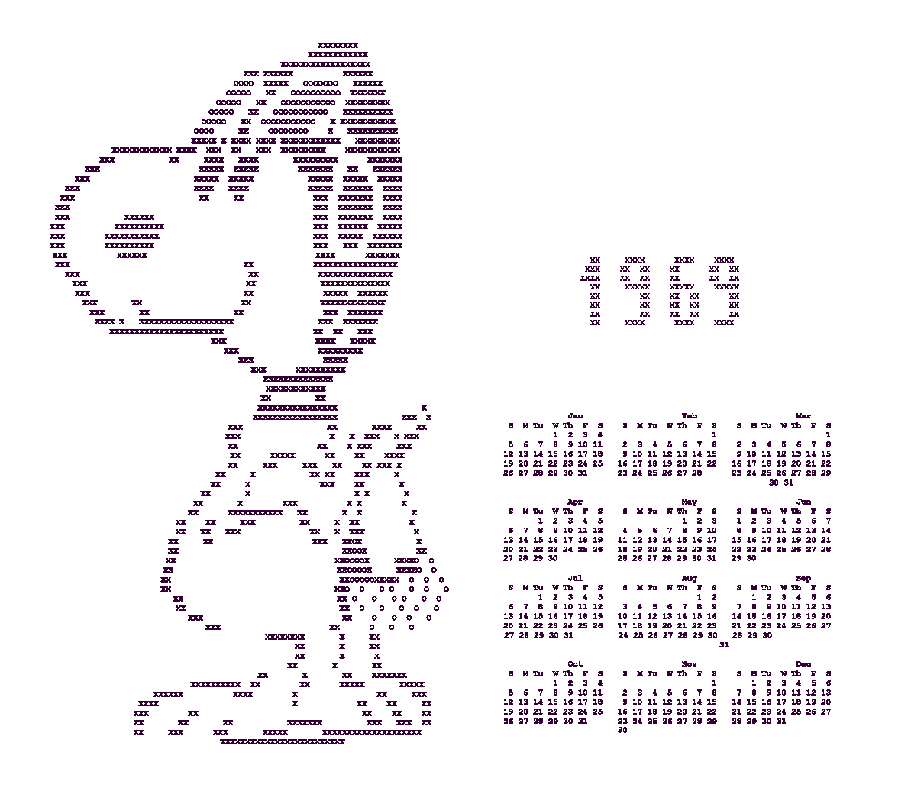
I have a certain fondness for this particular gimmick which I can’t quite explain. Perhaps it is the fact that it provides a feasible and exciting challenge for me – that of making my own Snoopy calendar. I have actually done this a couple of times. This time I used a combination of C programming and several Unix programs like enscript, figlet, cal, and sed.
There are three components to the Snoopy calendar. The first is the Snoopy ASCII/line printer art, the second is the calendar, and the third is the year number banner. These components must be pasted together in the same text file, which can then be converted to Postscript for printing. The Unix paste program is not satisfactory for this, since it doesn’t align the text, so I wrote my own program. Here is the final result:
1 /*************************************************
2 * Paste V. 1.0 *
3 * *
4 * Description: Pastes two files side-by-side *
5 * with the edges aligned. Does not work with *
6 * files that contain tabs. *
7 * *
8 * Author: Michael Warren *
9 * License: Micheal Warren Free Software License *
10 * Date: November 13, 2016 *
11 *************************************************/
12
13
14 #include <stdio.h>
15 #include <stdlib.h>
16 #include <string.h>
17 #include <errno.h>
18
19 // Maximum line length
20 #ifndef _MAXLL_
21 # define _MAXLL_ 80
22 #endif
23
24 struct line{
25 int linenum;
26 int linelen;
27 char text[_MAXLL_]; // Text of line
28 struct line *next; // Next line in current file
29 struct line *corr; // Corresponding line in other file
30 };
31
32 struct line *topl; // Top of left file
33 struct line *topr; // Top of right file
34 struct line *curl; // Current line in left file
35 struct line *curr; // Current line in right file
36
37 int main( int argc, char **argv ){
38 FILE *l, *r; // left and right files
39 int llen = 0, rlen = 0; // Number of lines in each file
40 int rmaxll = 0, lmaxll = 0; // Length of longest line in each file
41 if( !argv[1] || !argv[2] ){
42 printf( "\nUsage:\n%s <leftfile> <rightfile>\n\n", argv[0] );
43 return 1;
44 }
45 if( (l = fopen( argv[1], "r" )) == NULL ){
46 fprintf( stderr, "%s: ", argv[0] );
47 switch( errno ){
48 case EPERM : fprintf( stderr, "Operation not permitted.\n" ); break;
49 case ENOENT : fprintf( stderr, "%s: No such file or directory.\n", argv[1] ); break;
50 case EINTR : fprintf( stderr, "Interrupted system call.\n" ); break;
51 case EIO : fprintf( stderr, "Input/outpur error.\n" ); break;
52 case EDEADLK : fprintf( stderr, "Deadlock avoided.\n" ); break;
53 case ENOMEM : fprintf( stderr, "Cannot allocate memory.\n" ); break;
54 case EACCES : fprintf( stderr, "Permission denied.\n" ); break;
55 case ENODEV : fprintf( stderr, "Operation not supported by device.\n" ); break;
56 case EISDIR : fprintf( stderr, "%s is a directory.\n", argv[1] ); break;
57 case EINVAL : fprintf( stderr, "%s: Invalid argument.\n", argv[1] ); break;
58 case ENFILE : fprintf( stderr, "Too many open files in system.\n" ); break;
59 case EMFILE : fprintf( stderr, "Too many open files.\n" ); break;
60 case EFBIG : fprintf( stderr, "File %s is too large.\n", argv[1] ); break;
61 default : fprintf( stderr, "An error occurred. Error #: %d\n", errno );
62 }
63 return errno;
64 }
65 if( (r = fopen( argv[2], "r" )) == NULL ){
66 fprintf( stderr, "%s: ", argv[0] );
67 switch( errno ){
68 case EPERM : fprintf( stderr, "Operation not permitted.\n" ); break;
69 case ENOENT : fprintf( stderr, "%s: No such file or directory.\n", argv[2] ); break;
70 case EINTR : fprintf( stderr, "Interrupted system call.\n" ); break;
71 case EIO : fprintf( stderr, "Input/outpur error.\n" ); break;
72 case EDEADLK : fprintf( stderr, "Deadlock avoided.\n" ); break;
73 case ENOMEM : fprintf( stderr, "Cannot allocate memory.\n" ); break;
74 case EACCES : fprintf( stderr, "Permission denied.\n" ); break;
75 case ENODEV : fprintf( stderr, "Operation not supported by device.\n" ); break;
76 case EISDIR : fprintf( stderr, "%s is a directory.\n", argv[2] ); break;
77 case EINVAL : fprintf( stderr, "%s: Invalid argument.\n", argv[2] ); break;
78 case ENFILE : fprintf( stderr, "Too many open files in system.\n" ); break;
79 case EMFILE : fprintf( stderr, "Too many open files.\n" ); break;
80 case EFBIG : fprintf( stderr, "File %s is too large.\n", argv[2] ); break;
81 default : fprintf( stderr, "An error occurred. Error #: %d\n", errno );
82 }
83 return errno;
84 }
85 topl = (struct line *) malloc( sizeof( struct line ) );
86 topr = (struct line *) malloc( sizeof( struct line ) );
87 curl = topl; curr = topr;
88 char c;
89 // Build left file:
90 while( (c = fgetc( l )) != EOF ){
91 ungetc( c, l );
92 curl->next = (struct line *) malloc( sizeof( struct line ) );
93 curl = curl->next;
94 fgets( curl->text, _MAXLL_, l );
95 curl->linelen = strlen( curl->text );
96 lmaxll = (lmaxll < curl->linelen)?(curl->linelen):lmaxll;
97 curl->text[strlen( curl->text )-1] = '\0';
98 curl->linenum = ++llen;
99 }
100 // Build right file:
101 while( (c = fgetc( r )) != EOF ){
102 ungetc( c, r );
103 curr->next = (struct line *) malloc( sizeof( struct line ) );
104 curr = curr->next;
105 fgets( curr->text, _MAXLL_, r );
106 curr->linelen = strlen( curr->text );
107 rmaxll = (rmaxll < curr->linelen)?(curr->linelen):rmaxll;
108 curr->text[strlen( curr->text )-1] = '\0';
109 curr->linenum = ++rlen;
110 }
111 const int llenc = llen;
112 const int rlenc = rlen;
113 // Extend right file if shorter:
114 if( llen > rlen ){
115 int diff = llen - rlen;
116 for( int i = 0; i < diff; i++ ){
117 curr->next = (struct line *) malloc( sizeof( struct line ) );
118 curr = curr->next;
119 for( int j = 0; j < rmaxll; j++ ){
120 (curr->text)[j] = ' ';
121 }
122 (curr->text)[rmaxll] = '\0';
123 curr->linenum = ++rlen;
124 }
125 }
126 // Extend left file if shorter:
127 else if( llen < rlen ){
128 int diff = rlen - llen;
129 for( int i = 0; i < diff; i++ ){
130 curl->next = (struct line *) malloc( sizeof( struct line ) );
131 curl = curl->next;
132 for( int j = 0; j < lmaxll; j++ ){
133 (curl->text)[j] = ' ';
134 }
135 (curl->text)[lmaxll] = '\0';
136 curl->linenum = ++llen;
137 }
138 }
139 // Begin paste operation
140 curl = topl; curr = topr;
141 unsigned int len = (llenc < rlenc )?llenc:rlenc;
142 for( int i = 0; i < len; i++ ){
143 curl = curl->next;
144 curr = curr->next;
145 printf( "%s ", curl->text );
146 int lendif = lmaxll - curl->linelen;
147 for( int j = 0; j < lendif; j++ ){
148 putchar( ' ' );
149 }
150 printf( "%s", curr->text );
151 lendif = rmaxll - curr->linelen;
152 for( int j = 0; j < lendif; j++ ){
153 putchar( ' ' );
154 }
155 putchar( '\n' );
156 }
157 while( (curl = curl->next) != NULL ){
158 curr = curr->next;
159 printf( "%s %s\n", curl->text, curr->text );
160 }
161 // Cleanup:
162 curl = topl->next; curr = topr->next;
163 while( curl != NULL ){
164 struct line *auxl = curl->next;
165 free( curl );
166 curl = auxl;
167 }
168 while( curr != NULL ){
169 struct line *auxr = curr->next;
170 free( curr );
171 curr = auxr;
172 }
173 free( topl ); free( topr ); fclose( l ); fclose( r );
174 return 0;
175 }
I created the banner using the following command:
figlet -f banner 1969 | sed "s/ / /g" | sed "s/#/##/g" | sed "p"
The three sed commands are there to double the width and height of the banner. It results in the following output:
## ########## ########## ##########
## ########## ########## ##########
#### ## ## ## ## ## ##
#### ## ## ## ## ## ##
## ## ## ## ## ## ##
## ## ## ## ## ## ##
## ############ ############ ############
## ############ ############ ############
## ## ## ## ##
## ## ## ## ##
## ## ## ## ## ## ##
## ## ## ## ## ## ##
########## ########## ########## ##########
########## ########## ########## ##########
I then did some manual editing to round out the corners. I put this output above the output of cal -y 1969 in Vim, and then ran the program that I had written to paste it onto a Snoopy ASCII picture (I used a different picture this time). I then ran it through enscript, using landscape orientation and reducing the text size to it would all fit on one page, and also telling it to run in line printer emulation mode.
The final result:

10 ways to lose an argument
For the record, if you have to do any of these things during an argument, then you’ve already lost:
- Attacking the other person’s physical appearance, sexual prowess, social status, etc.
- Correcting the other person’s spelling or grammar (unless it’s so bad that you literally cannot understand what they’re saying, but this is almost never the case)
- Countering an argument in favor of social progress with “That’s the way it is. Deal with it.”
- Asking the other person to provide sources for something that it’s impossible to provide sources for (like an opinion)
- Stating that the other person has no right to attack your point of view because it is your opinion
- Using cute emoticons as a substitute for an argument
- Refusing to justify your position on the grounds that it is obvious (this is a favorite tactic among SJWs)
- Backing up your argument with articles on obscure news sources that no one but you has ever heard of (this is a favorite among Trump supporters) – if you can’t find it in a reputed news source, then it’s not news.
- Pulling stuff out of your ass (I’m looking at you, Jack Posobiec.)
- Pointing out your own credentials, unless those credentials are actually relevant to the subject of the argument, rather than just a way to prove that you’re smarter than the other person because you have a degree
Reverse engineering Apple’s in-terminal emojis
I found a somewhat interesting feature in the Apple terminal, supported by both Terminal.app and iTerm2. Essentially, it allows for the printing of emojis in the terminal. I discovered this when I noticed that the Homebrew package manager prints beer and tap emojis when it is downloading and installing packages. I was curious about how these emojis are represented, so I used a program that I had written, called hex, which essentially just displays the hex values of characters entered by the user. I’ve used this program to find escape sequences for things like function keys and the like, allowing me to implement these inputs in my programs.
Here is the source code for hex. It’s a fairly simple program…
1 // This program displays the octal, hex, decimal,
2 // and byte character representations of characters
3 // typed at the terminal.
4
5 #include <stdio.h>
6 #include <termios.h>
7 #include <signal.h>
8
9 struct termios term;
10 struct termios save;
11
12 void stop( int );
13 void cont( int );
14
15 int main( int argc, char **argv ){
16 tcgetattr( 0, &term );
17 save = term;
18 term.c_lflag &= ~( ICANON | ECHO | ECHONL );
19 signal( SIGINT, stop );
20 signal( SIGTSTP, stop );
21 signal( SIGCONT, cont );
22 tcsetattr( 0, TCSANOW, &term );
23 // Section where the program executes
24 // in raw mode:
25 unsigned char c;
26 for(;;){
27 c = (unsigned char) getchar();
28 printf( "%3o\t%2x\t%3d\t%c\n", c, c, c, c );
29 }
30 // End raw mode:
31 tcsetattr( 0, TCSANOW, &save );
32 return 0;
33 }
34
35 // Restores terminal settings before allowing
36 // the signal.
37 void stop( int signum ){
38 tcsetattr( 0, TCSANOW, &save );
39 signal( signum, SIG_DFL );
40 raise( signum );
41 }
42
43 // This function undoes the cleanup performed
44 // by stop() when the process is suspended.
45 void cont( int signum ){
46 tcsetattr( 0, TCSANOW, &term );
47 signal( SIGTSTP, stop );
48 }
I copied the beer mug emoji from the terminal after downloading a package. I then started the hex program and hit Command-V, then copied the hex bytes (there were four of them) by hand into a file using a hex editor. To test it, I ran cat on the file I had created, and lo and behold – a beer emoji was printed to my terminal.
I then decided to test a concept, the concept of printing emojis in a program. I used assembly language for this, because I’m not entirely sure of the proper syntax for C, and I thought it would be faster to write if I did it in assembler. I tested several codes, and then when I found the result, I wrote a comment in the source file indicating what the emoji was. Be warned – this code is extremely tedious, even for an assembly program.
1 global start
2
3 segment .data
4 str1: db 0xf0,0x9f,0x8d,0xb0,0x0a,0x00 ; Cake emoji
5 str2: db 0xf0,0x9f,0x8d,0xba,0x0a,0x00 ; Beer emoji
6 str3: db 0xf0,0x9f,0x8d,0xa9,0x0a,0x00 ; Donut emoji
7 str4: db 0xf0,0x9f,0x8d,0x8e,0x0a,0x00 ; Apple emoji
8 str5: db 0xf0,0x9f,0x8d,0x81,0x0a,0x00 ; Maple leaf emoji
9 str6: db 0xf0,0x9f,0x8d,0x82,0x0a,0x00 ; Leaf emoji
10 str7: db 0xf0,0x9f,0x8d,0x97,0x0a,0x00 ; Drumstick emoji
11
12 segment .text
13 start:
14 push dword 5
15 push dword str1
16 push dword 1
17 mov eax,4
18 sub esp,4
19 int 0x80
20
21 push dword 5
22 push dword str2
23 push dword 1
24 mov eax,4
25 sub esp,4
26 int 0x80
27
28 push dword 5
29 push dword str3
30 push dword 1
31 mov eax,4
32 sub esp,4
33 int 0x80
34
35 push dword 5
36 push dword str4
37 push dword 1
38 mov eax,4
39 sub esp,4
40 int 0x80
41
42 push dword 5
43 push dword str5
44 push dword 1
45 mov eax,4
46 sub esp,4
47 int 0x80
48
49 push dword 5
50 push dword str6
51 push dword 1
52 mov eax,4
53 sub esp,4
54 int 0x80
55
56 push dword 5
57 push dword str7
58 push dword 1
59 mov eax,4
60 sub esp,4
61 int 0x80
62
63 push dword 0
64 mov eax,1
65 sub esp,4
66 int 0x80
Here is what I get when I run the program:
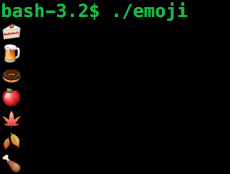
It’s not particularly useful, especially considering that these emojis are not portable to other systems, but it’s an interesting concept to test. It’s kind of confusing that the emojis use four bytes each, whereas the UTF-8 character set used by the terminal uses three bytes for each Unicode character. I’m not sure how Apple implemented this.
BSD Unix hack: adding conditional preprocessing capabilities to calendar
One of the most useful features of the GNU Compiler Collection is the -D option to cpp, which allows you to define macros at the command line. This in combination with #ifdefs and #ifndefs in the C/C++ source files allows for very versatile conditional compilation, because it allows you to set certain parameters that the program uses without having to edit the original source code. You can use this to, say, compile a debugging version of a program, among other things.
It is widely known that the C/C++ languages use CPP for preprocessing. What is less well-known is the fact that calendar, the default BSD reminder program, also uses CPP. This is one advantage that calendar has over the newer and more feature-rich remind program, which, as far as I know, doesn’t use preprocessing. calendar is available for all major BSD variants, including macOS. It may have been ported to other *NIXs such as Linux, though I am not sure, and I don’t feel like looking it up right now.
calendar uses CPP to allow for the conditional inclusion of several libraries of pre-written reminders or events – from the standard run-of-the-mill dates like US holidays and birthdays of famous people, to more exotic things like important events in the history of computing, and important dates in the Lord of the Rings timeline. This is done in the obvious way:
# include <calendar.usholiday>
# include <calendar.birthday>
# include <calendar.computer>
# include <calendar.lotr>
You can also do #defines, with or without parameters:
#define PHYSICAL( TIME ) Appointment with -NAME REMOVED- for yearly physical at TIME
#define PSYCH_APPT( TIME ) Appointment with -NAME REMOVED- at TIME
#define THERAPY( TIME ) Therapy appointment with -NAME REMOVED- at TIME
...
Jul 20 PSYCH_APPT( 3:00 PM )
Nov 15 PHYSICAL( 11:00 AM )
Nov 29 THERAPY( 2:00 PM )
Unfortunately, that’s about all you can do with CPP in the default calendar program. I decided I wanted to be able to include certain libraries conditionally, so that if I want to just view reminders for things I have to do in my own life, I have that option, and if I want to also check on upcoming holidays, or events in Tolkien’s universe, I can manipulate those options with a simple command line flag. The CPP code in my calendar file would then look something like this:
#ifdef _HOL_
# include <calendar.usholiday>
#endif
#ifdef _BDAY_
# include <calendar.birthday>
#endif
#ifdef _COMP_
# include <calendar.computer>
#endif
#ifdef _LOTR_
# include <calendar.lotr>
#endif
… And I would manipulate these options from the command line using a parameter like -D_COMP_.
So I got to work writing a frontend for calendar that adds that capability. Here is the result, written in bash and sed:
#!/usr/bin/env bash
# This script is a frontend for the calendar program that adds the
# full power of cpp to calendar. Namely, it can do conditional
# preprocessing and #includes based on arguments given by the -D
# option to CPP.
declare -i DAYS=10
# Parse command line options:
for arg in "$@"
do
case "$arg" in
-W ) shift; let DAYS=$1; shift;;
-B ) shift; let DAYS=-$1; shift;;
-D ) shift; break;; # Define CPP macros
-* ) shift; shift;;
esac
done
# Debugging info:
#echo "DAYS=$DAYS"
#echo "\$1=$1"
#echo "\$2=$2"
# Preprocess calendar file and run it through a sed script that performs necessary edits
cpp -D${1:-"NULL1"} -D${2:-"NULL2"} -D${3:-"NULL3"} -D${4:-"NULL4"} -I /usr/share/calendar ~/.calendar/calendar 2>/dev/null | sed -f ~/Scripts/calendar.sed >| ~/calendar.tmp
# Print output of calendar
if [[ $DAYS -gt 0 ]]
then
# Print forward
command calendar -f ~/calendar.tmp -W $DAYS
elif [[ $DAYS -lt 0 ]]
then
# Print backward
let DAYS=-$DAYS
command calendar -f ~/calendar.tmp -B $DAYS
fi
# Cleanup
rm ~/calendar.tmp
unset arg DAYS
The accompanying sed script:
#!/usr/bin/env sed
/^#/d
/^[0-9][0-9]*\/[0-9][0-9]* /s/ /\ /
/^[A-Z][a-z]* [0-9][0-9]* /{
s/ /\ /
s/ /\ /
s/\ / /
}
After this I set an alias in my .bashrc file to have the calendar command run this script, rather than running the calendar program directly.
There are some problems with this script, the main one being that it is extremely slow, sometimes taking as long as 10-15 seconds to do the preprocessing. If I rewrote this program in C, I could speed it up by a few orders of magnitude, not only because C is inherently faster, but also because it exposes more of the underlying details of how everything is implemented, which allows you to program more intelligently and optimize your program for the hardware.
For example, I don’t know for sure whether comparing two integers is faster than comparing two strings in the bash shell (a problem I ran into here when trying to decide whether to just use a “true”/”false” string to determine whether to use -B or -W; the bash shell doesn’t have Boolean types), because I don’t understand the underlying implementation. I would have to spend days studying the source code for the shell to get a sense of how to optimize everything. All I know is that all shell variables are essentially strings, so it’s not the same as C, where comparing two integers is much faster than going through two character arrays and comparing each pair of characters one by one. In the bash shell, you have to convert the numerical strings to numbers, perform an arithmetic or comparison operation on them, and then convert them back to strings. Both methods are extremely inefficient. This is what I don’t like about extremely high-level scripting languages such as Unix shell, Python, Ruby, PHP, etc. But hey, they allow you to write programs a hell of a lot faster than C, which is better if you just want a quick-and-dirty solution to a programming problem.
Donald Trump wins
Man, it’s been a long time since I’ve posted. I’ve kind of abandoned the Internet for a while, well, not really abandoned it; more like I’ve just become a lurker. I’m going to try to post more regularly now. Let’s go over what’s going on…
Okay, there’s the election of Donald Trump, obviously. Everyone’s been talking about it for the past few days. I’m sitting in a bagel shop right now and there’s a bunch of old guys sitting at the table next to me talking about him; not sure if they support him or not. Yeah, we just chose a self-entitled spoiled brat with no political experience and a very poor grasp of reality to be the most powerful man in the world. Happy thoughts.
I’m going to be honest. I’m actually happy that Trump got elected, and I’m looking forward to his presidency, because we’re going to see a very entertaining poetic justice unfold. There’s going to be a poetic justice on two fronts. First of all, we have the pleasure of watching Trump actually try to follow through with what he says he’s going to do. We get to watch him actually try to build the border wall, and actually try to get Mexico to pay for it. We get to see him actually try to tell China that we’re not going to pay off our debt to them. We get to see him actually try to kick out all the Muslims and Mexicans. We get to see him actually try to put Hillary Clinton in jail, and sue all the women who accused him of sexual assault. It’s going to be very entertaining, maybe even hilarious, to see all these grandiose plans fail spectacularly.
Tronald Dump, as I like to call him, is about to get a nice dose of reality. He’s gone through his entire life never having to suffer any consequences for anything he does. He’s been taught that he can have a business fail on its ass and still come out on top without having to work hard at all. He’s been taught that he can sexually assault women and evade taxes, as well as systematically destroy thousands of official documents to obstruct civil cases (which is a federal crime by the way; yes, #thedonald is actually a felon), and get away with it. He was born rich and has lived a life of bliss and privilege; he hasn’t earned shit. He has built his career by exploiting others and manipulating the system.
Well, Karma always has a way of finding you, and it always gets you eventually. Pretty soon Trump is going to get a dose of Karma that he will never recover from. He’s going to have the most difficult job in the world, and he’s going to fail dramatically, and everyone is going to hate him. There will be massive demonstrations in Washington D.C., maybe even riots. People won’t leave him alone. He will try to sue anyone who says anything negative about him, only to find that, OMG, you’re not above criticism, especially now that you’re a political figure. #thedonald is going to have his first ever taste of defeat, at the ripe age of 50-something.
The second poetic justice is what is going to happen to all the redneck Trump supporters who are acting all smug over his victory right now. You know, the ones who are all like “Grab the popcorn and watch these liberals cry. Hahah!” Thing is, most of these people are uneducated hillbillies who are probably working as bus drivers, construction workers, waiters, or some other low-paying job. They’re not rich big business owners, you know, the one group of people that Trump actually cares about. The people who are laughing now are the same people that Tronald Dump is going to screw over in the next four years.
So yeah, rednecks, in a couple years, when you’re getting paid ten cents an hour to work in a sweatshop in life-threatening conditions for 70 hours a week, let’s see if you’re laughing then. Let’s see if you’re laughing when you’re living in your pickup truck because you had to sell your trailer to feed your twelve kids. Let’s see if you’re laughing when you lose your health insurance, and have to shell out tens of thousands of dollars in medical bills when you get in your next hunting accident. Yeah, let’s see who’s laughing then.
As a wise man once said, he who laughs last, laughs best.
Creating an MS-DOS floppy image from a directory in Unix
For a long time I have needed a way to transfer data into my DOS virtual machines. I came somewhat close to a solution by using Keka to archive directories as ISO files, but I was unable to create what I truly needed – a floppy disk image containing the archived contents of a directory. Well, now I’ve found a way to do just that, partly by doing some research on Google and partly by just figuring stuff out on my own.
The first thing you need to do is create a 1.44 MB empty file with an extension of .ima, .img, or some other raw floppy image extension. This can be done using dd, with the following command:
dd if=/dev/zero of=floppy.img bs=1024 count=1440
I took a screenshot of the output of dd for a visual:

The next step is to format the file with an MS-DOS FAT filesystem. The easiest way to do this is in DOS. So insert the blank disk image in the VM and type format a:
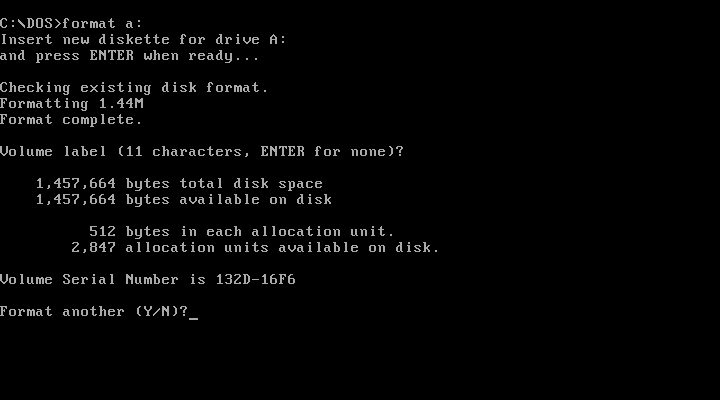
Now you have a blank floppy image and are ready to add files to it. To verify that the floppy had been formatted, I ran a hexdump in the Unix terminal.
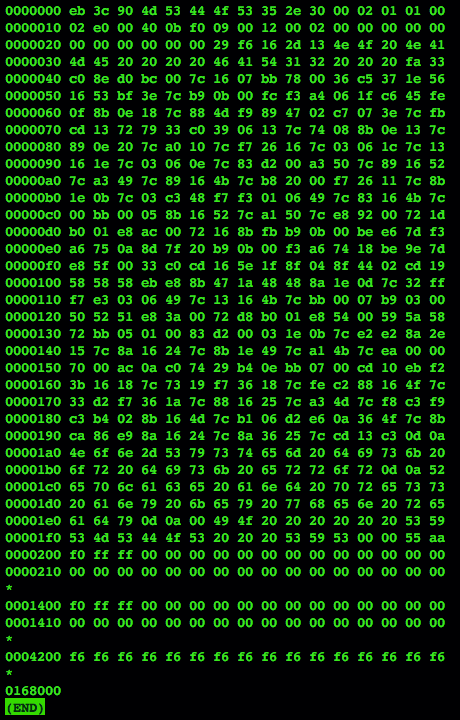
Next you need to mount the floppy image. The easiest way to do this is to just double click on its icon in the GUI, then copy and paste the files from the source directory or directories to the directory that the image is mounted on. I tested this first with a couple of simple standalone programs – Visicalc and DOS Cal:
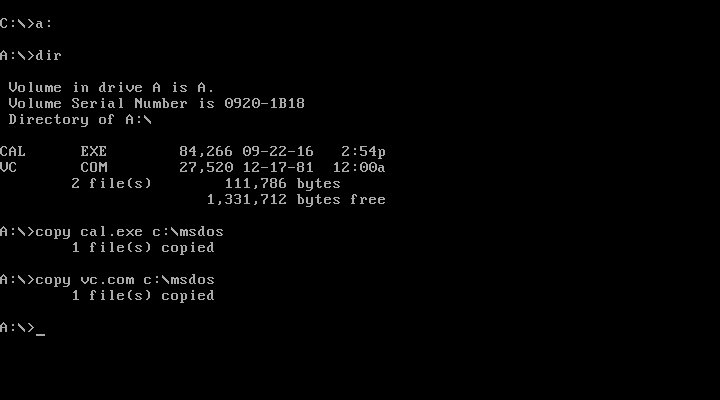
Now I have installed two programs: CAL.EXE and VC.COM. Indeed, when I go to the C: drive and type cal, the program starts.
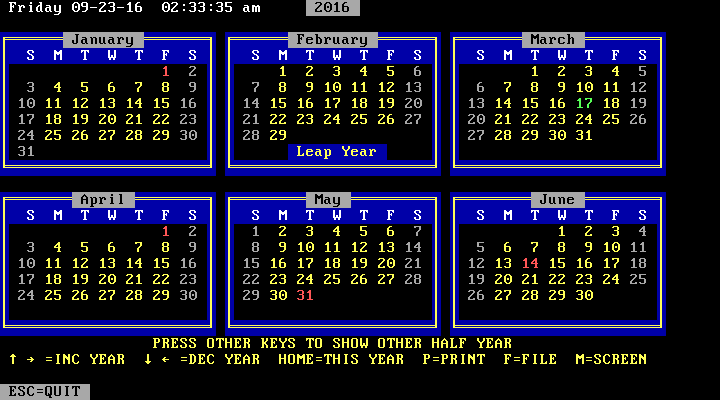
Just a side note here: the default path in MS-DOS is set to C:\DOS, so if you want to run programs from a different directory you need to edit the search path in the AUTOEXEC.BAT file:
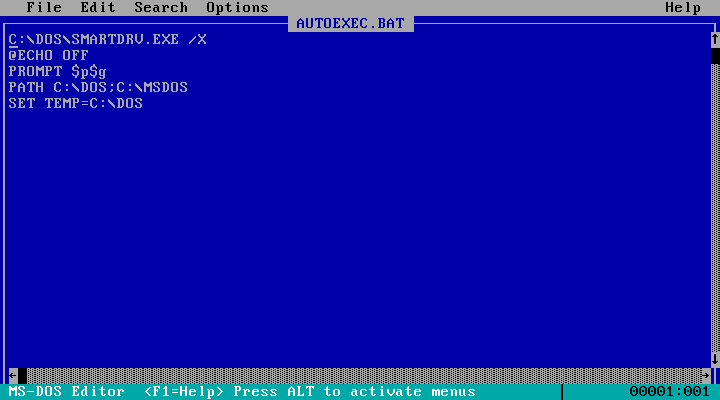
For some reason, my DOS VM would only read the first floppy image that I created. Creating further floppy images using the same technique resulted in an Abort-Retry-Fail error message. To work around this, I have written a C program that automates the process of creating and formatting the floppy image, using the hexdump of the original image. That way I know the file will be exactly the same and I’ll be able to create multiple floppy images for software that requires a multi-disk installation. I will talk about this program, as well as MS-DOS 6.22, MS-DOS disk labels, and some additional software that I’ve installed in the next few blog entries. For now, farewell.
How to create a PDF of a Unix man page
Unix man pages are written in the troff language. There are three basic Unix programs that interpret troff code – nroff, troff, and groff. nroff is used for preparing documents for display in the terminal. troff prepares documents to be printed on phototypesetters, a technology that is pretty much obsolete by now. The Unix man program is essentially just a frontend for nroff that preprocesses the code with a set of macros known as the man macros and then pipes it into less.
What we will be using is the GNU roff program, or groff. groff is a troff interpreter that converts the troff code to Postscript. In order to apply the command, you first have to locate the man page you want to convert. On my system, most of the man pages are located in /usr/share/man. Let’s say we want to convert the file nmap.1 into Postscript. We would use a command like this:
groff -man /usr/share/man/man1/nmap.1 > nmap.ps
The -man option tells groff to run the code through the man macro package, which is the macro package used for man pages, before sending its output to the Postscript file.
Now we have a Postscript file, which is fairly easy to convert to a PDF. Many document viewing programs (such as Apple Preview) will automatically convert a Postscript file to a PDF when you open it. Alternatively, if you just want a hard copy, you can skip the PDF and send the Postscript file directly to a printer using the lp command. The only requirement is that it must be a Postscript printer, which the majority of printers on the market nowadays are.
Setting up an Apache HTTP server
Through some config file hacking, I have managed to set up an Apache HTTP server on my Macbook. I did this so that I could test the full functionality of PHP. Since PHP is one of the top most needed skills for freelance coding jobs, I figured it would be a good idea to learn it, and of course to use any of the features of PHP beyond just the core language, you need a web server.
Starting the Apache server is pretty easy. All you have to do is type sudo httpd at the command line (assuming Apache is installed on your system, which I think it is for most Unix-based systems). It is recommended that you use apachectl as a frontend instead of using httpd directly, but I couldn’t seem to get this to work, so to start Apache I use sudo httpd and to stop it I use sudo killall httpd.
Now configuring the server to use PHP was somewhat more difficult, though still not too much so. First of all, for a server to use PHP, the PHP DOS initialization file needs to be present as /usr/local/lib/php.ini. After some digging around, I found the PHP ini file at etc/php.ini.default, so I just copied it (changing the filename of course).
The next thing I had to do was tell Apache to load the PHP module at startup. This is done by editing the file /etc/apache2/httpd.conf and uncommenting the appropriate code line. It must be remembered that editing this file requires root privileges.
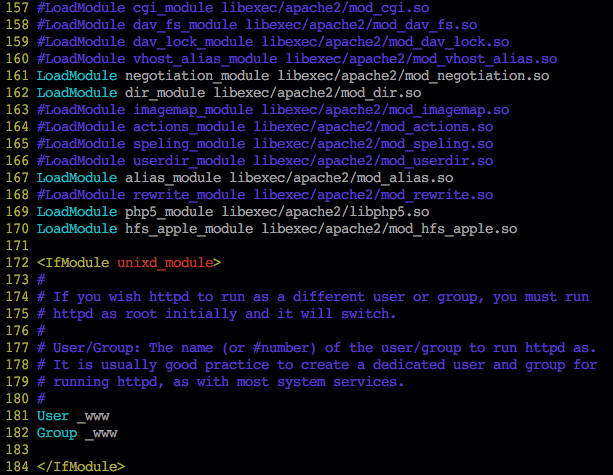
The appropriate line is
LoadModule php5_module libexec/apache2/libphp5.so
…Shown here already uncommented.
The next thing you have to do is find out what directory Apache is using to serve files to clients. This is determined by the DocumentRoot environment variable, and controlled by a <Directory> tag.
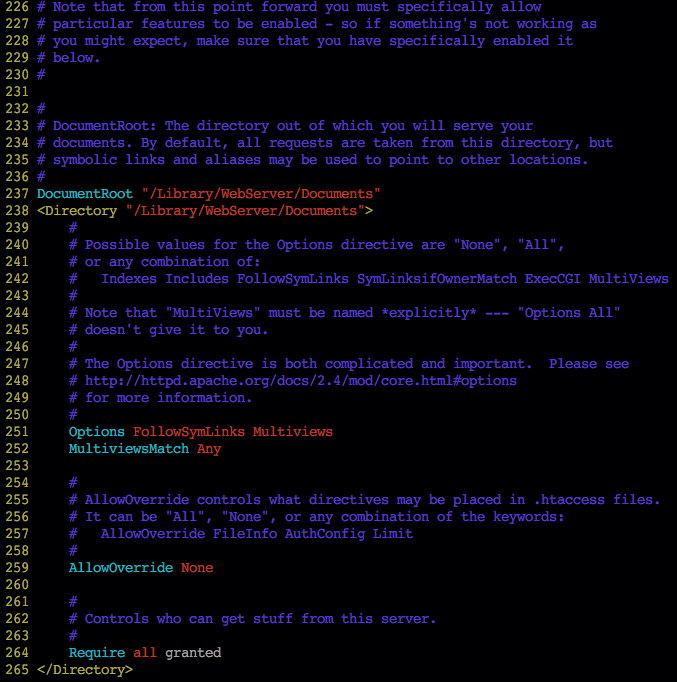
Here we see that the server’s filesystem is rooted at /Library/WebServer/Documents. Of course this is Mac-specific, and the root will be different on other systems, and we can also change it, though I felt no need to.
If you title a document “index.html”, “index.php”, etc. then this will be the file that the client goes to when the user types your domain name without appending a path at the end. Also, if you title a document, say, my-pictures.html, the file extension can be omitted in the URL.
